„Zehntausende winzige chemische Fabriken“ Bei Digitalisierung weltweit führende Enzymdatenbank aus Braunschweig wird Kerndatenbank
Die „Digitalisierung“ ist in aller Munde. Vor mehr als 30 Jahren aber stieß Professor Dietmar Schomburg, heute Inhaber einer Niedersachsenprofessur am Braunschweiger Zentrum für Systembiologie (BRICS), mit seiner Vision auf Unverständnis: „Ich träumte von einer wissenschaftlichen Datenbank, auf die jeder jederzeit zugreifen kann. Sie sollte die wichtigsten Eigenschaften von Tausenden Enzymen, einem Lebensbaustein, enthalten.“ Das Internet gehörte noch lange nicht zum Alltag, wissenschaftliche Artikel fand man in dicken Büchern in Bibliotheken, Wissenschaftlerinnen und Wissenschaftler schrieben Briefe statt E-Mails.
Inzwischen ist der Fortschritt ohne Datenbanken nicht mehr denkbar – es gibt Zehntausende. Da kann man lange recherchieren und auch mal den Überblick verlieren. Deshalb gibt es sogenannte Kerndatenbanken oder auch „Core Data Resources“, die als unverzichtbar eingestuft werden. Ein internationales Expertengremium hat 18 Monate lang Datenbanken analysiert und einige dieser „Kerndatenbanken“ ausgewählt. BRENDA, kurz für „BRaunschweiger ENzym-DAtenbank“ und Schomburgs ganzer Stolz, gehört jetzt dazu.

Professor Dietmar Schomburg, Bildnachweis: Julia Helmecke/TU Braunschweig
Wichtige Quelle für Agrarwissenschaft, Biologie und Brauwesen
„Enzyme gehören zu den Eiweißstoffen und sind winzige chemische Fabriken in der Zelle, die Leben überhaupt ermöglichen“, erklärt Schomburg. Sie formen unsere Nahrung in Energie und körpereigene Stoffe um, sie steuern das Gehirn genauso wie die Verdauung und das Wachstum. Sie sorgen dafür, dass unsere genetischen Informationen abgelesen werden können. Sie erlauben Pflanzen zu wachsen und Bakterien, sich schnell zu vermehren – oder Krankheiten zu verursachen. In großen Bioreaktoren erlauben sie uns die Produktion von Arzneimitteln und auch von Bier.
Die Enzymdatenbank ist also wichtig für die Arbeit in vielen Bereichen – von der Ernährungswissenschaft über Biotechnologie und Pharmazeutik bis hin zur Botanik, Zoologie, Mikrobiologie und auch im Brauwesen. Sogar Hausärztinnen und Hausärzte können in dem Wissensfundus mit 150 Millionen Datensätzen Antworten finden – wie zum Beispiel auf die Frage: Warum ist ein bestimmtes Enzym im Magen nicht stabil?
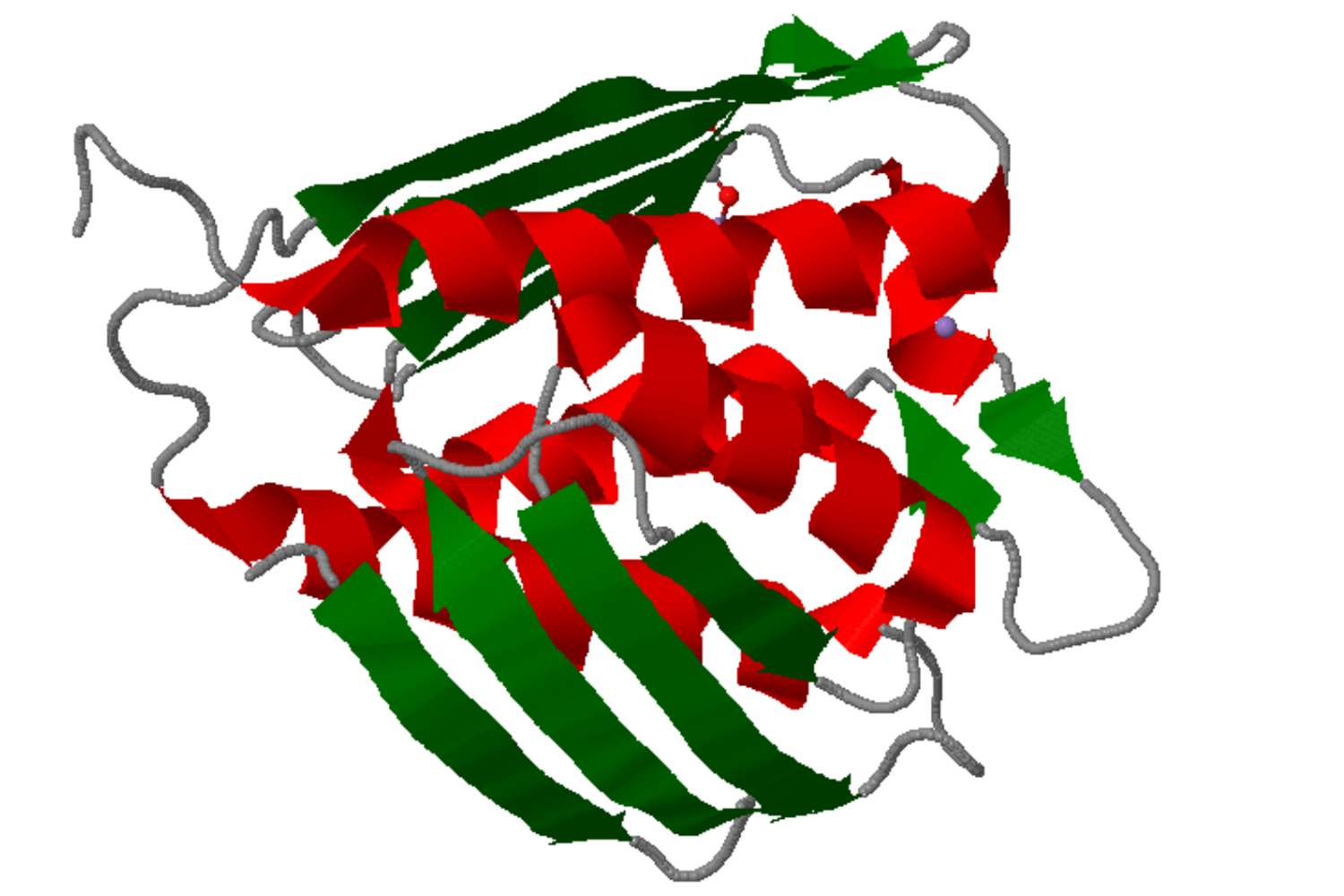
Ein Enzym aus dem Tuberkulose-Erreger (imidazoleglycerol-phosphate dehydratase), Bildnachweis: BRENDA
Eine halbe Millionen Nutzer
Schomburg zeigt begeistert, was die Datenbank leisten kann. Sie katalogisiert zum Beispiel, in welchen Organismen welche Enzyme vorkommen, bei welcher Temperatur sie aktiv sind und welche Inhibitoren das Enzym steuern und stoppen können. Welche Stoffwechselprodukte produzieren sie und wie arbeiten verschiedene Enzyme zusammen? Neben ihren Strukturen und Netzwerken kann die Datensammlung Proteine auch visuell darstellen – so kann sich der Nutzer die dreidimensionale Struktur eines Proteins anzeigen lassen. Eine halbe Millionen Nutzer pro Jahr wüssten diese Recherchefunktionen zu schätzen, so Schomburg.
Dann öffnet der Professor einen Büroschrank mit Dutzenden Büchern. Auf je 700 Seiten enthalten sie Enzymdaten, die von 1987 bis 2013 in die Datenbank eingepflegt wurden. Heute kann man alle diese Daten im Internet abrufen – und das ohne Zugangsbeschränkung. Diese Open-Access-Policy war übrigens auch eines der Kriterien, dass BRENDA zur „Kerndatenbank“ ernannt wurde.

Die Enzyme-Datensammlung als Springer-Handbuch, Bildnachweis: János Krüger/TU Braunschweig
Die Anfänge in Braunschweig
Schomburg erinnert sich an die Anfänge 1987 in Braunschweig: „Ich konnte den damaligen Leiter der Gesellschaft für Biotechnologische Forschung (GBF), dem Vorgängerinstitut des Helmholtz-Zentrums für Infektionsforschung (HZI) für meine Idee gewinnen. Professor Joachim Klein stellte die finanziellen Mittel zum Start des Projektes zur Verfügung.“ Man begann, wissenschaftliche Artikel auszuwerten und die wichtigsten Ergebnisse auf den Computer zu übertragen. Als Schomburg 1996 Braunschweig verließ, nahm er das Projekt mit an seinen Lehrstuhl an der Universität zu Köln. „Als ich 2007 an die TU Braunschweig berufen wurde, kehrte BRENDA an seinen Ursprungsort zurück“, sagt Schomburg.
Die Herausforderungen
Eine der größten Herausforderungen war die Finanzierung. Über die Jahre suchte Schomburg immer wieder neue Quellen, zwei Jahre hielt er das Projekt allein mit privaten Mitteln über Wasser. Nicht zu unterschätzen ist die Programmierarbeit, die in der Entwicklung der Datenbank steckt. Die anfänglich einfach strukturierte Datenbank musste sich im Laufe von 30 Jahren weiterentwickeln und sich mehrfach neu erfinden. Enzymdaten, im Gegensatz zu den Genomdaten, bestehen nicht nur aus Zahlen und Buchstaben, sondern auch aus Bilddaten und Strukturen und Netzwerken, die zeigen, wie Enzyme zusammenarbeiten, um dem Organismus die notwendigen Verbindungen zu liefern.

Das Entwicklerteam der Braunschweiger Enzymdatenbank BRENDA mit Projektleiter Professor Dietmar Schomburg. Bildnachweis: Marcus Ulbrich/TU Braunschweig
Anerkennung für Lebenswerk
Im Juni 2018 hat BRENDA den Ritterschlag der Datenbank-Jury bekommen und ist seitdem Bestandteil des weltweiten ELIXIR-Datenbank-Netzwerks. Als die Nachricht über die internationale Anerkennung seines Lebenswerkes hereinflattert, freut sich Professor Schomburg. „Noch wichtiger ist mir aber, dass die langfristige Weiterfinanzierung von BRENDA gesichert ist“, sagt Schomburg. „Ich hatte sehr großes Glück mit meinen Mitarbeiterinnen und Mitarbeitern. Ohne deren Engagement und Ideen wäre der Erfolg nicht möglich gewesen.“ Und wer hätte das damals gedacht – Braunschweig spielt mit diesem Projekt in der ersten Liga der Digitalisierung mit.